 Smilingleo's Blog
Smilingleo's Blog如何打造一个serverless的微信小程序
January 11, 2020
动机
应用需求
因为笔者在外企工作,英语是第二工作语言,不断学习、提高英语水平成了一个必不可少的日常。而在英语学习中,一个很重要的环节就是背单词,是的,很枯燥的那个背单词。
对一般人来说,背单词的第一目的是认识单词,也就是在阅读英文文章、看邮件的时候碰到单词能知道什么意思,但是在一个外企工作环境里面,参加各种线上线下会议,能听懂别人说的也很重要,所以,背过的单词还需要能听懂,当然,最终还需要能用得上,用准确的词汇来描述事情,也就是要能输出。 输出的过程比较复杂,需要有受众,需要交互,比较难于程序化。
市场的有很多的背单词软件,也有很多创新的通过阅读、朗诵、听力等等来达到背单词效果的应用,可用过一些之后,或多或少都有点这样那样的问题。因为本篇重点是介绍技术的文章,所以不详细对比各家软件的优劣及各自问题了。
我心目中理想的背单词软件是:
- 好的遗忘算法。背单词就是不断重复,什么时候重复很重要,Spaced Repetition遗忘算法在这个领域很流行,万能的记忆辅助软件Anki就是基于这个算法。
- 权威的内容。很多单词软件中的单词解释都断章取义,或者只给简单的中文解释,这就造成很多时候用词不准确,因为你背的单词中文解释太笼统。需要有英文解释,有例句。比如:
meeting, 简单的背单词软件只是给你个中文翻译:会议、会合,于是有人在翻译公司年会的会时,第一个想到的就是company meeting,哈哈 。 - 有语音。语音一则可以验证自己的发音是否准确,另外可以用来向耳朵单向输入。当然,语音最好能是完整的句子,这样才能知道如何应用。
- 充分利用整段时间结合零碎时间。可以在整段时间背诵,也很好地可以利用坐公交、上大号等零碎时间。
基于此,就有了自己开发一个背单词应用的想法,随后就有了《世凝听记》。
技术需求
前端
说完功能上的需求,需要再考虑一下技术方面的情况。总的来说,我希望开发一个手机上的应用,而不是电脑端的,毕竟现代人已经离不开手机,而且手机功能也足够强大。
手机应用又可以细分,到底是开发个原生的app,还是用类似React Native开发个可以跨平台的,然后分别发布到安卓和苹果应用商店?不过感觉都太麻烦了,最后决定还是选择微信小程序吧,主要原因:
- 小程序天然跨平台,同时支持安卓、苹果
- 免去各种应用商店发布上架的麻烦,毕竟一个人无法对接那么多的商店
-
小程序的基本功能也足够,毕竟我们需要的只是:
- 简单页面
- 语音播放
- 后台交互
后端
后端需要实现的功能可以简单概括为:
- Anki集成(可以实现背单词,还不知道什么是Anki的请自行问度娘)
- 单词语音制作、历史文件的存储 (订制单词语音)
- 简单的用户管理
开发后端第一个冒出来的想法是需要个服务器,可随便哪个平台,哪怕租个最低配的服务器每年也得上千的成本,对于这个以自用为出发点的小应用成本太高了。一些免费的PAAS比如Salesforce的Heroku倒是可以考虑,但是Heroku生态里面的服务也比较有限,而且还考虑将来如果万一用户量多了,Heroku扩展也稍差了些。
最后,还是选择了AWS,因为开发这个应用需要:
- 无服务器托管后台代码,那自然是选择AWS
Lambda。 - 提供一个API,供小程序调用,所以,我们需要AWS
API Gateway。 - 文字转语音服务,试了一下AWS
Polly,感觉也不错。 - 语音文件的存储,开始可能文件比较少,但是如果用户量增大,系统的扩展就是个挑战,在AWS上文件管理当然是
S3。 - 用户信息管理。一提到信息管理,自然而然就会想到数据库,可数据库服务一般都是最昂贵的部分,咱这个人爱好可别被AWS
RDS账单上N位数金额给打击喽。仔细想想本着一个绿色软件的开发原则,我们也不需要用户注册等步骤,只要是微信用户就可以使用,也不需要了解你的个人信息,所以决定这个部分也用S3来解决。
技术实现
架构

这其实也谈不上什么架构,太简单了:小程序发送API请求给API Gateway,API Gateway转发给Lambda,Lambda调用Polly API创建语音,然后Lambda将创建好的语音存储到S3。
组件描述
下面分开介绍一下每一种技术,以及在使用过程中遇到的一些问题及解决办法。
AWS Polly
《世凝听记》最开始也是最核心的需求,就是将文字转换成语音,AWS Polly就是这样一个服务。Polly的使用非常的简单,就是普通的API的调用,加上一些简单的Speech Synthesis Markup Language(SSML)知识。
引入包:
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-java-sdk-polly</artifactId>
<version>1.11.77</version>
</dependency>
因为语音中需要来回切换中英文两种语言,而Polly现在还无法做到自动无缝地切换两种语言,所以只能通过元数据来提示,这就是SSML
为了方便,我将这些做了简单封装,查看 Polly.java, 使用的时候只需要调用:
Polly polly = new Polly(config);
polly.encodeEnglish("Hi there, I'm Leo, glad to meet you!");
polly.encodeChinese("大家好,我叫大宝,很高兴见到大家!");
之后就是区分中英文,调用相应API了。识别文字的语言大概可以通过字符的编码来进行,汉字字符集在Unicode中的编码有一个范围:
public static boolean isChinese(char c) {
Character.UnicodeBlock ub = Character.UnicodeBlock.of(c);
if (ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS
|| ub == Character.UnicodeBlock.CJK_COMPATIBILITY_IDEOGRAPHS
|| ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS_EXTENSION_A
|| ub == Character.UnicodeBlock.GENERAL_PUNCTUATION
|| ub == Character.UnicodeBlock.CJK_SYMBOLS_AND_PUNCTUATION
|| ub == Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS) {
return true;
}
return false;
}
比如,单词accused有一个例句:
例:The fifteen accused, young men from different parts of England, denied the charges.被告是15名来自英格兰各地的年轻男子,他们对指控矢口否认。
英文句子夹在中文之间,那么就需要通过上面工具来识别中英文,可以将英文过滤掉只剩下中文,然后调用polly.encodeChinese(...),然后再把中文过滤掉,剩下英文,之后调用polly.encodeEnglish(...)。
AWS Lambda
Lambda是函数式编程里重要的一个概念,AWS把他们的产品命名为Lambda,一定程度上,也是让大家直观地将一个Lambda抽象为一个Function。FP里面很注重没有副作用,最常见的副作用就是I/O。有点编程经验的人都知道,I/O是无法避免的,所以AWS把所有I/O相关的部分也都剥离为单独的服务,比如数据库RDS,Dynamo,对象存储S3等等,剥离了这些之后,Lambda本身就是没有副作用的了(宏观意义上,变量级别side effect是微观意义上的,这里不需要较真)。
和FP里面的副作用扯上关系有点牵强,不过说Lambda是stateless应该没问题。正因为无状态,你的代码才可以被自动的部署/运行/下架,而与计算环境无关,可以在任何一个Runtime上运行。真正做到按需付费!
当然,这都是有代价的。代价就是如果你的lambda在没有负载的情况下,会被停止运行,新请求来了的时候,需要先部署、启动你的服务,这就意味着你的API性能波动会比较大。如果你的API响应时间是100ms,而你的服务启动时间需要3s,那么一个请求可能就需要超过3100ms的响应时间。这也就意味着,最好不要用很臃肿的开发框架,比如你开发个lambda费要用上SpringBoot,之后你就得头疼性能问题了。
使用Lambda最大的好处是:你每个月可以享受一百万次请求的免费额度,超过才付费。如果你需要更快的响应时间,那你可以配置你的lambda一定的预留concurrency,这样系统响应会更快,但是也就意味着你会多花钱。
AWS Lambda支持的开发语言很多,我用的Java,主要是考虑Java操作字节码及Stream相比Node容易些。
实现一个Lambda很简单,只需要定义一个class,实现com.amazonaws.services.lambda.runtime.RequestHandler接口,比如:
package example;
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
public class Hello implements RequestHandler<Integer, String>{
public String handleRequest(Integer myCount, Context context) {
return String.valueOf(myCount);
}
}
将代码打包为jar,上传到AWS Lambda,然后指定Handler的方法名:example.Hello::handleRequest就好了。
关于调试,你常用的调试技巧依旧有效,你可以通过写log,log内容会被AWS CloudWatch记录下来。当然,你也可以在本地通过单元测试队这些代码进行调试,这样你就可以设断点跟踪,你可能需要Mock一些服务,总之,写容易测试的代码会让你的调试变得简单。
关于Lambda的粒度,有人会将Lambda拆分的很细,当然这与你的代码模块化有关,可以每一个API创建一个Lambda,这样的好处就是你可以灵活地定义不同API的性能参数;升级一个API的时候不会影响到其他的API。如果需要整合这些小粒度API,提供一个更大的功能,可以使用AWS Step Function,将这些小的API像工作流一样组合起来,相当灵活。
当然,灵活的同时也带来了一定的运维负担。
对于本项目这种简单的应用,我只是简单地将所有API合并在一个Lambda里了,通过一个command参数来区分是哪个API。当然,这也是因为微信小程序在调用后台服务的时候采取的保守的做法,只能调用预定义的URL。
AWS S3
S3(Simple Storage Service)可以算是AWS最成功的服务了,号称可以在任何时候,任何地点,存取任意大小的文件,不过确实很方便。
在本系统里,S3的目录结构如下:
users // bucket
+--<wechatId> // 每个用户一个独立的folder
+-- userInfo.json //用户信息,包含wechatId, 创建时间,上次登录时间,剩余点数(用来防止滥用),偏好等。
+--audio
+-- <timestamp>.mp3 // 历史音频文件
+-- <timestamp>.txt // 历史音频对应的单词
如果需要读取某个用户的信息,或者查看其语音制作历史,仅仅需要知道用户的wechatId,然后访问相应的文件就可以了。这种用法基本上等同于将S3当作一个文档数据库在用。
读取用户信息的代码片段:
String userInfoPath = ... // 组装userInfo的路径信息
S3Object object = null;
try {
object = s3Client.getObject(USER_BUCKET_NAME, userInfoPath);
// 从S3Object中读取文件内容为字符串
String jsonString = IOUtils.toString(object.getObjectContent());
// 字符串反序列化为Object
userInfo = objectMapper.readValue(jsonString, UserInfo.class);
userInfo.setLastLogin(now.toString());
} catch (IOException e) {
throw new IllegalStateException("Invalid userInfo.json content found.", e);
} finally {
IOUtils.closeQuietly(object, log);
}
另外一个重要的操作是写文件到S3。前文中我们知道,polly.encodeEnglish(...)返回是字节数组,也就是音频文件的字节编码,保存文件就是需要将这些字节写入到S3中:
// 音频字节码
byte[] audioBytes = polly.encodeChinese("hello world");
// 创建写入S3的InputStream, 作为PutObjectRequest的构造参数。
try (ByteArrayInputStream baIn = new ByteArrayInputStream(audioBytes)) {
// 文件元数据,下载文件的时候会有用
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentType("audio/mpeg3");
metadata.addUserMetadata("x-amz-meta-title", format("%s.mp3", timeStamp));
metadata.setContentLength(audioBytes.length);
final String fileName = format("%s/audio/%s.mp3", wechatId, timeStamp);
log.info(format("writing file: %s, size: %d", fileName, audioBytes.length));
// 构建写入请求
PutObjectRequest putRequest = new PutObjectRequest(USER_BUCKET_NAME, fileName, baIn, metadata);
// 写入数据
s3Client.putObject(putRequest);
}
AWS API Gateway
在创建Lambda的时候,需要指定如何来触发这个function,这里我们当然是用API Gateway了。下面就是一个用API Gateway定义一个API,调用Lambda的流程示意图。
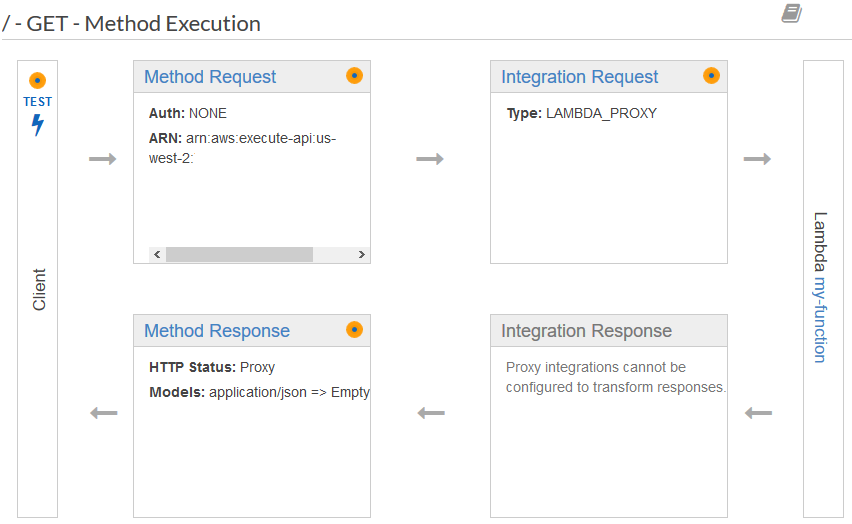
从上图中可以看到,在一个请求从进入API Gateway之后,到发送到Lambda之前,有两个环节Method Request, Integration Request,我们可以响应地定义API的请求格式、身份验证、参数等等,还可以对request body进行简单处理。
而在Lambda返回结果,到返回客户端之间,也有两个环节:Integration Response, Method Response,这两个在本应用中比较重要。
从Lambda的定义我们可以看出,Lambda只能返回一个类型的response,那么问题来了:如何在碰到不同类型的Exception的时候返回不同的HTTP Response Code呢? 比如,如果碰到InvalidArgumentException,应该是客户端发送的请求有格式等问题,理应返回400错误,而服务器端错误应该返回500,但是Lambda怎么让API Gateway知道?
在刚开始用Gateway的时候,我确实遇到了这个问题,所有的API Response Code都是200,结果导致在微信小程序端的错误处理不起作用。查看文档之后才发现这个问题。解决办法其实也简单:根据Lambda返回内容做正则匹配,如果有errorMessage field(注意,必须是这个名字),那就会匹配Integration Response中定义的正则规则,比如,如果errorMessage是以ServerSideException开头,那就返回500。我们就可以配置为:Lambda Error Regex: ServerSideException.*。
API Gateway很灵活,能做很多扩展,但是价格相对较贵,如果我们只是简单的API,可以使用AWS新的HTTP API。
微信小程序
微信小程序的开发教程网上太多了,我这里就不多说了。
我只是简单仿造官方的组件展示小程序,照猫画虎就好了。只是在开发过程中需要自己找下图标素材,调试一下CSS样式,让页面更好看、更符合常人的使用习惯些。
微信小程序作为微信的一种功能扩展,本质上是在微信的进程中提供了一个运行第三方插件运行的Runtime,这个本质也决定了微信小程序的优缺点:简单,但功能受限。
如果有React, Vue,Angular等MVVM框架的使用经验,小程序开发上手十分容易。不过想做一些相对复杂些的功能就比较受限了,连最基本的在界面上选择文字这种操作都需要特殊的操作。
让我最不能接受的是,纵观整个小程序开发官方文档,对于单元测试几乎算是完全忽略了,只能找到单元测试章节,跟着介绍走完结果发现根本行不通。而且更加不可理解的是:搜索了网上很多小程序样例代码库,居然没有找到一个包含单元测试的例子!!!管中窥豹,由此可见腾讯对于代码质量的价值观是什么样的。
小程序的发布需要先通过审核,审核的同学会帮你做简单的sanity测试,也算是一个小福利。
小程序后台还提供访问流量统计信息,也是一个相比开发native app的好处之一。
Anki
集成Anki主要有两个技术问题:
- 如何解析Anki卡组
- 如何调用AnkiWeb API
Anki卡组包解压后其实就是一个SqlLite数据库,库表结构可以参考这个文章。重要的是两个表:note(单词)和card(记录选项历史等信息)。
所有的Anki客户端都需要和AnkiWeb同步,所以才可以实现跨平台,多种客户端一起用。所以,我们可以直接集成AnkiWeb的后台系统。
AnkiWeb后台的几个API如下:
登录
登录需要首先访问登录页面,解析html来获取CSRF令牌,之后就可以通过:
curl -i -H ":authority: ankiweb.net" -H ":method: POST" -H ":path: /account/login" -H ":scheme: https" -H "x-requested-with: XMLHttpRequest" https://ankiweb.net/account/login -d submitted=1 -d csrf_token=<csrf_token> -d username=<username> -d password=<password>
成功之后会设置ankiwebcookie,用于后续API。
列出所有卡组
curl -i -H "cookie: ankiweb=<cookie>" -H ":authority: ankiweb.net" -H ":method: GET" -H ":path: /decks/" -H ":scheme: https" -X GET https://ankiweb.net/decks/
选择卡组
在背单词之前,必须先选中一个卡组,这也是在anki各种客户端之间同步的时候,只运行一个会话的原因。
curl -i -H "cookie: ankiweb=<cookie>" -H ":authority: ankiweb.net" -H ":method: POST" -H ":path: /decks/select/<deck_id>" -H ":scheme: https" -H "x-requested-with: XMLHttpRequest" https://ankiweb.net/decks/select/<deck_id>
获取卡牌(同时提交上批卡牌的答案)
curl -i \
-H "cookie: ankiweb=<cookie>"\
-H ":authority: ankiuser.net"\
-H ":method: POST"\
-H ":path: /study/getCards"\
-H ":schemested-with: XMLHttpRequest"\
-X POST https://ankiuser.net/study/getCards -d answers=[] -d ts=1577326449902
answers参数例子:
answers: [
[
1468852725069, // card id
3, // answer index
845294 // the duration in milli-seconds starting from the card is shown to the moment it's answered.
],
[1468852727608,3,11486],[1468852726783,2,41176],[1468852725289,2,25019],[1468852727583,3,15638]
]
这个API算是一石二鸟,不过总觉得API的命名上有问题:POST /study/getCards,POST是写,getCards是读,组合在一起就感觉莫名其妙了。
成本
从本小程序发布到现在,有一个多月了,下面是我在AWS上的账单:

是的,你没有看错,一个月2美分!!!
账单全是S3的API调用开销。当然,这基本上只是自己一个人用的成本,如果用的人多了,超过了那些free tiers,成本还是会上来的。也是基于此,在小程序方面也做了一些简单的限制,如果超过一定用量,会被限制。
心得体会
-
兴趣驱动
整个开发完全是兴趣驱动,如果没有兴趣可能不会涉猎微信小程序的开发以及像AWS Polly等服务的学习。
所以,兴趣是帮助你提高的初始动力。
-
全栈的胜利
整个应用端到端的开发用了大概一周的时间,API设计、界面设计、服务实现,如果不是全栈,可能你就得找到志同道合的的互补方(估计一般是前端),花大量时间沟通,尝试并行开发,然后联调,效率肯定远远没有全栈高。
不过效率高是不是就一定好?沟通过程是否能够碰撞出更多的火花?或者发现设计上的潜在问题?这些问题可能永远没有绝对的对或者错,只能是合适的人用合适的方法才能有更好的产出。
最后,欢迎大家试用《世凝听记》。
